< Academy
When One LLM Isn’t Enough: How Multi-Agent Systems Work
Research

Dr Nadine Kroher
Chief Scientific Officer
Why teams of models often beat a single one and what’s changing under the hood
Large language models are powerful generalists, but when a system needs to handle dozens of different tasks, from answering support questions to querying databases, a single model can quickly become unwieldy.
The more instructions and edge cases you cram into one system prompt, the longer it becomes, the slower the responses, and the higher the cost per call. And because most user requests only touch a small slice of that prompt, much of that processing is wasted.
Multi-agent frameworks solve this by breaking the problem down. Instead of one model doing everything, you create a team of smaller, specialised agents each responsible for a specific kind of task and coordinated by an orchestrator.
In practice, a multi-agent system is simply a network of LLMs that collaborate. One agent receives the input, others handle subtasks, and an orchestrator routes information between them.
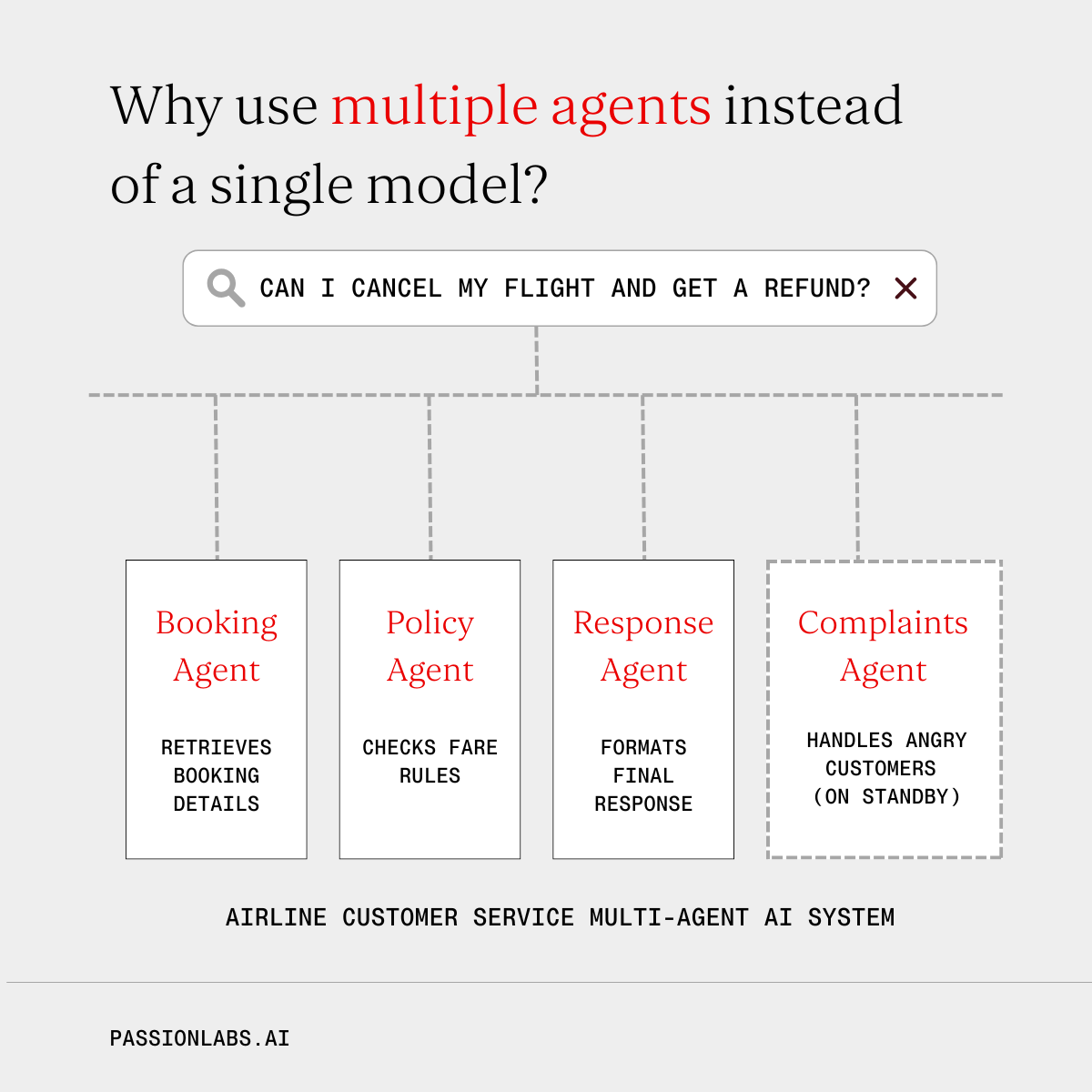
Example: imagine an airline’s customer service assistant.
Each agent has a focused role, a smaller system prompt and less room for confusion. This often means faster and more reliable results.
You don’t have to reinvent the wheel. Several SDKs already provide the core pieces: asynchronous task handling, message passing, memory, guardrails, and more.
Some popular choices include:
These toolkits handle the plumbing so you can focus on workflow logic and agent behaviour.
1. Deterministic pipelines
A fixed sequence of steps that always run in order. This is useful when the workflow never branches and each stage is predictable.
E.g. Answer query → Format in HTML → Send to user.
2. Orchestrator with tools
Here, the orchestrator dynamically decides which tools or agents to call based on the question. A tool might be another agent or a simple function, like fetching data from an API. This approach gives flexibility and can reuse the same agents for many tasks.
3. LLM as a judge
In some systems, two agents work in a feedback loop: one generates content, the other evaluates it.
Example: a generator produces SQL queries; an evaluator runs and checks them, giving feedback until a correct, efficient version emerges. This “self-critique” structure helps models refine their own output through iteration.
Guardrails
Safety agents monitor input and output to prevent prompt injection, data leakage, or policy violations. They run in parallel with the main workflow and can block or rewrite unsafe content before it reaches users.
Dynamic tool access
Different user roles can be mapped to specific tool permissions. For instance, a customer agent might only read from a database, while an internal agent can also write updates.
Parallel execution
Independent tools can run at the same time, reducing latency. For example, one agent fetches the total number of flights today while another fetches cancelled flights and the orchestrator calculates the percentage.
Multi-agent frameworks bring the same advantages as good team design in human organisations:
As these frameworks mature, they’re becoming less of a research toy and more of a production-ready architecture for scalable AI systems.
Multi-agent systems turn a single, monolithic prompt into a co-ordinated team of specialists. Done right, they make AI faster, safer, and easier to scale, not by inventing smarter models, but by designing smarter systems around them.
As the tools evolve, the question is no longer “What can one LLM do?” but “What can several LLMs achieve together?”
